
Introduction
Imagine you are a beginning data scientist. You are just starting out and don’t really know your way around the field yet. You then are asked to train a model based on a dataset given to you, and then test the model to see how it performs. However, you are only given one dataset to do all of this. How do you do it? Well, the answer is data splitting! In a talk by Cassie Kozyrkov, this is exactly what she talks about(the talk can be found here).
Summary of Video
Cassie starts out by showing us the power of having multiple datasets. With one dataset you can either validate an opinion or use it to form an opinion. With two datasets you can use one to form the opinion and use one to validate it. With three datasets, you can use one to form an opinion, one as intermediate testing, and once you have validated your opinion using the second dataset, you can use one last dataset to test it. This is really the standard you should aim for – 3 datasets(according to Cassie). Since we don’t have 3 datasets we can use data splitting to split our original dataset into 3 datasets as follows. We first split our original dataset into exploratory data and test data. Then we can further split the exploratory data into training data and validation data. To connect to before, the training data is the data we use to make our opinion. The validation data is the data we use to refine it, and we keep going back and forth between our training data and validation data until we are confident in our opinion. Finally, as one last test, we test our opinion on the final test data(the dataset we use to test our final opinion). Cassie emphasizes how this is extremely useful because now you have the ability to formulate an opinion based on data, see if it is even worth pursuing with the validation data, and then finally test it to see its actual accuracy using the test data. This is the power of data splitting. Below is a really good visualization of how this all works:
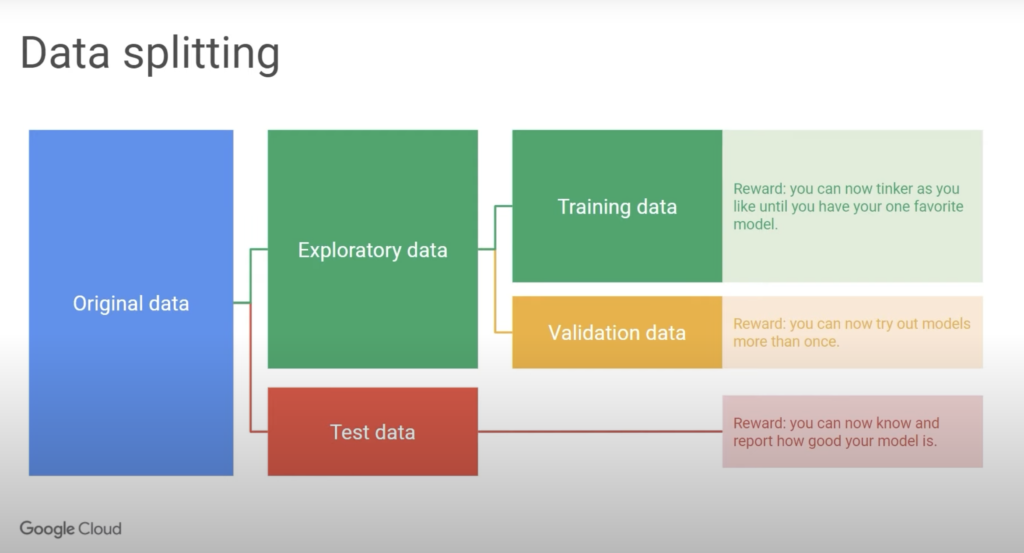
Credit: Video that post is based on(link found here). Timestamp in the video: 3:38
My Take
Overall, I liked the video. It was extremely informative. It also showed me the exact nature of data splitting – i.e. what parts get split into what and what each split part is used for. I also really liked the visuals presented in the video – they really aided in my understanding of the content. I also understand now how important data splitting can be and how helpful it can be. You can now basically have multiple datasets with one and have each one serves a purpose. This will cause your opinions on the dataset to be better and more accurate driving better insights. I can really attest to this as I have seen it help make ML models better and drive better insights. The information was also given in a very clear and concise way, while still not sacrificing content. This is extremely helpful because it shows that these concepts – at their core – are relatively simple, which really boosts your confidence.
Conclusion
All in all, this talk was a good one. It was extremely informative, while still being concise. It really helped me understand this concept in a more visual way. I highly recommend you watch it when you get the chance(the link to the talk can be found here).